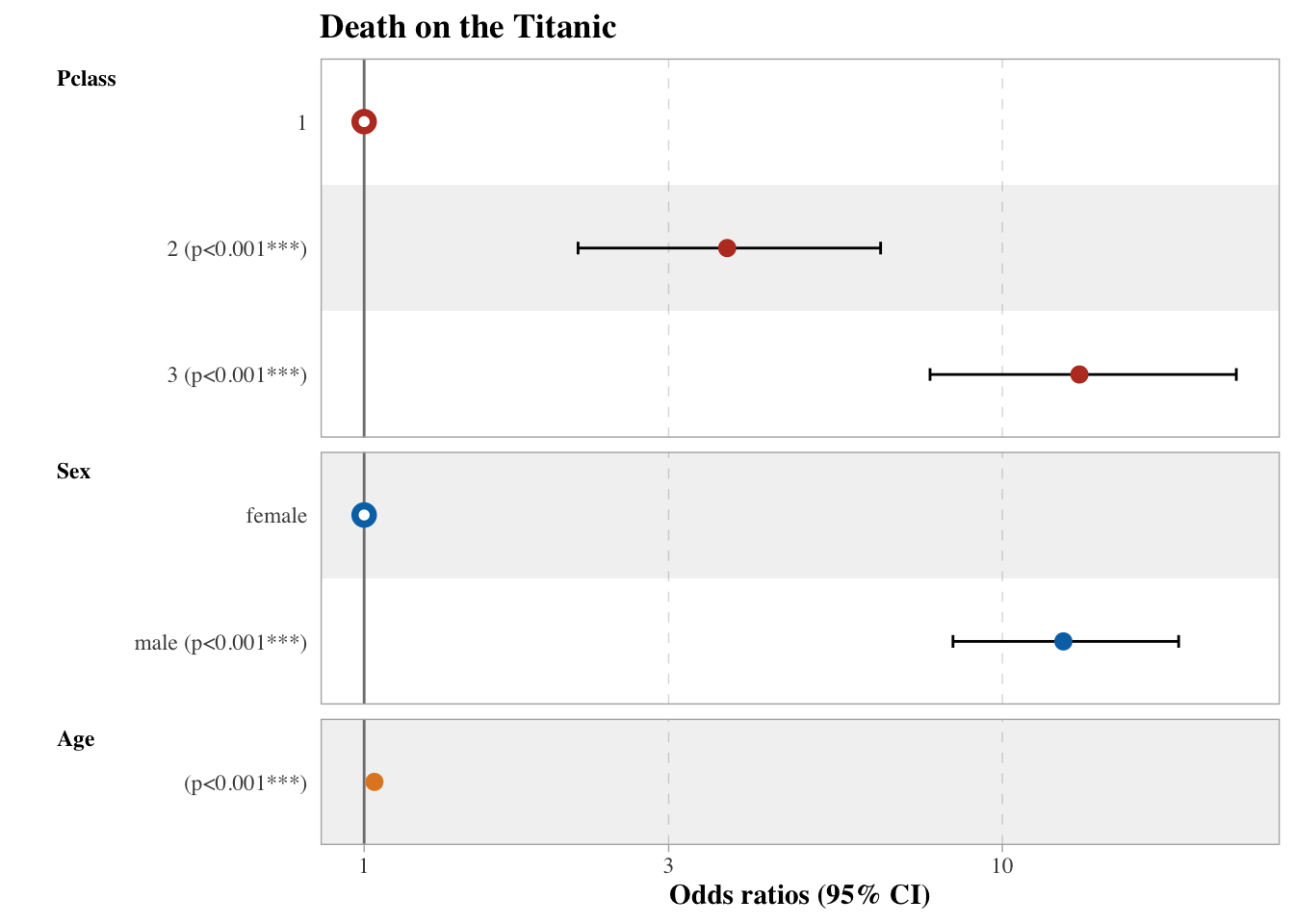
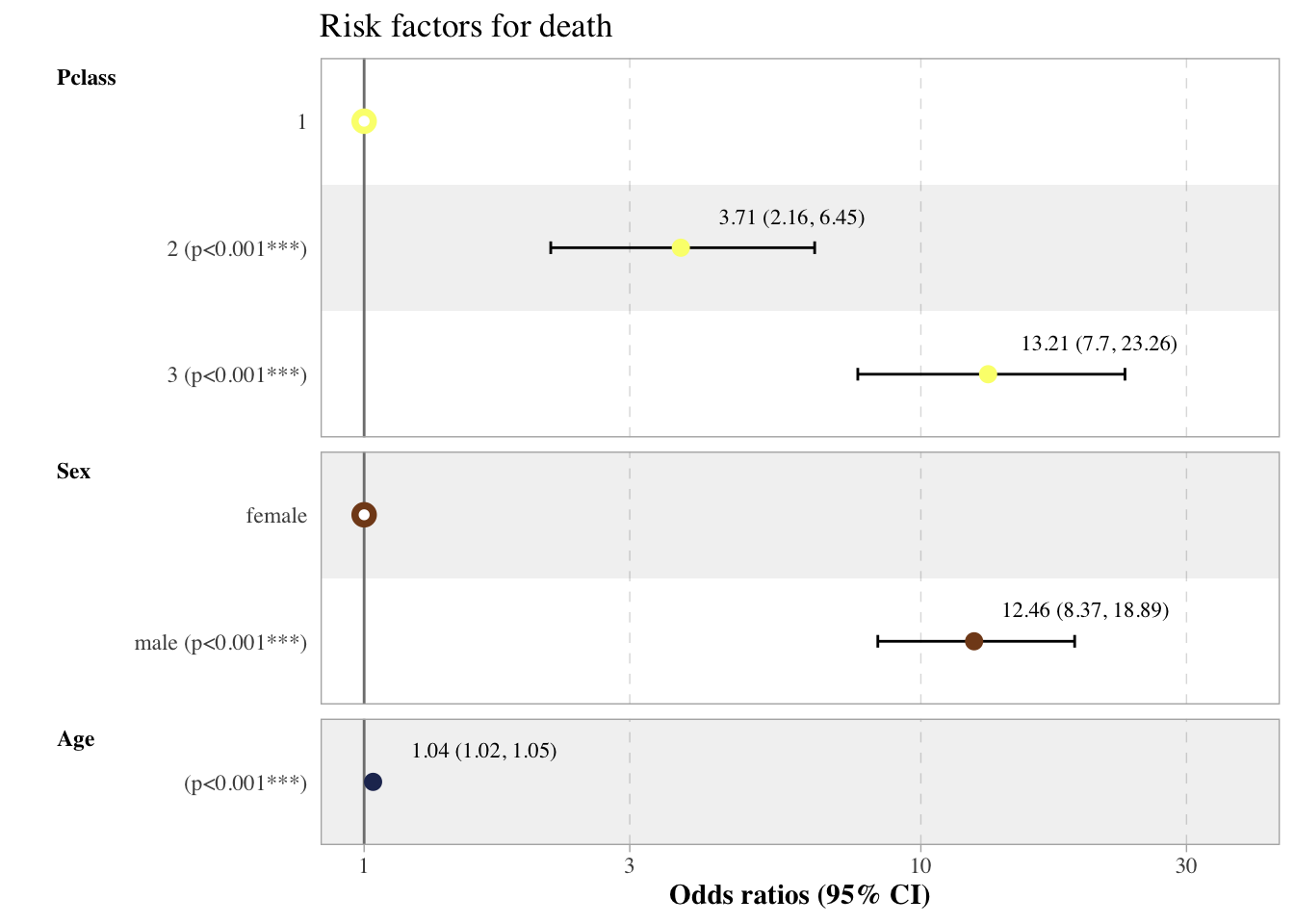
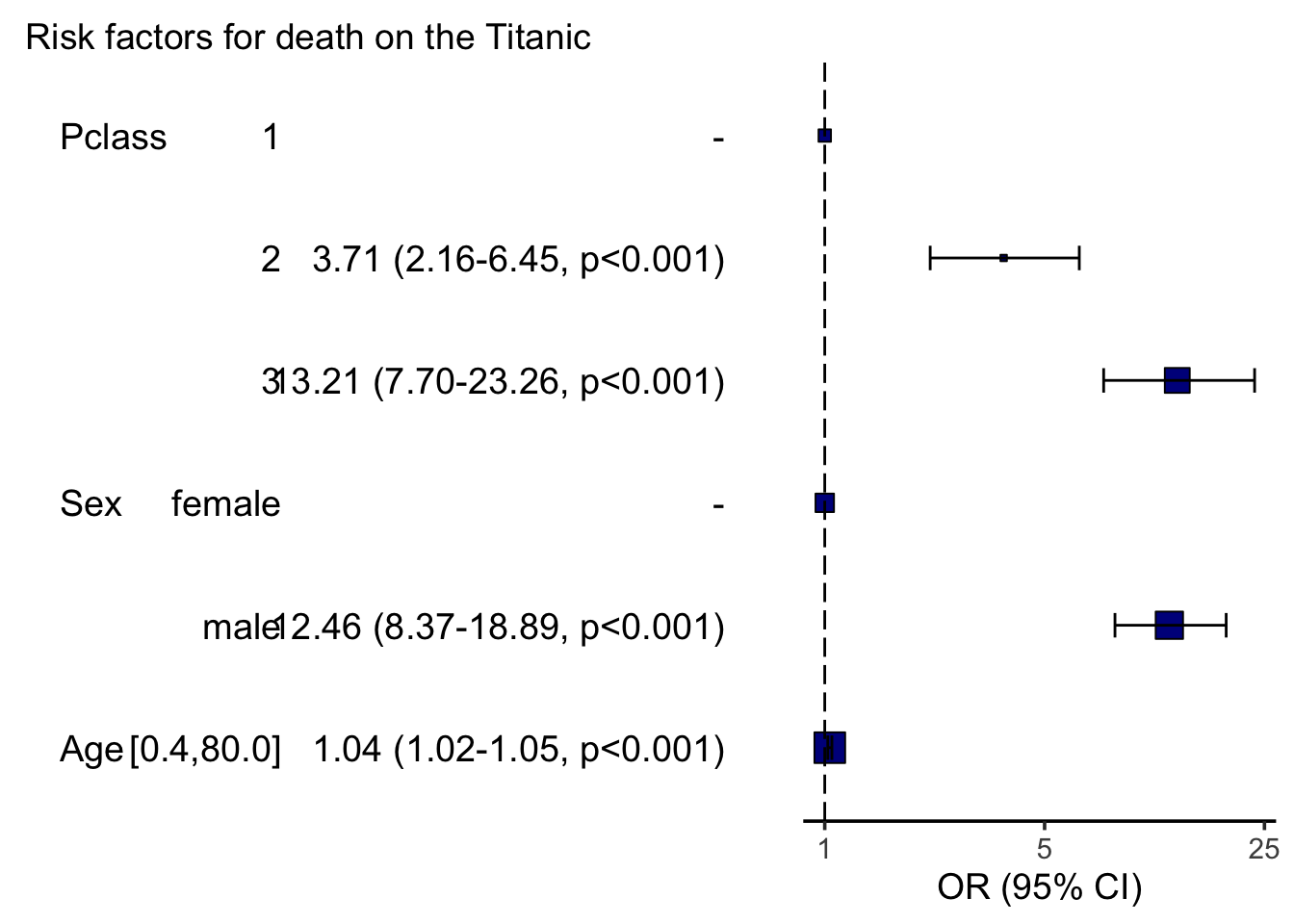
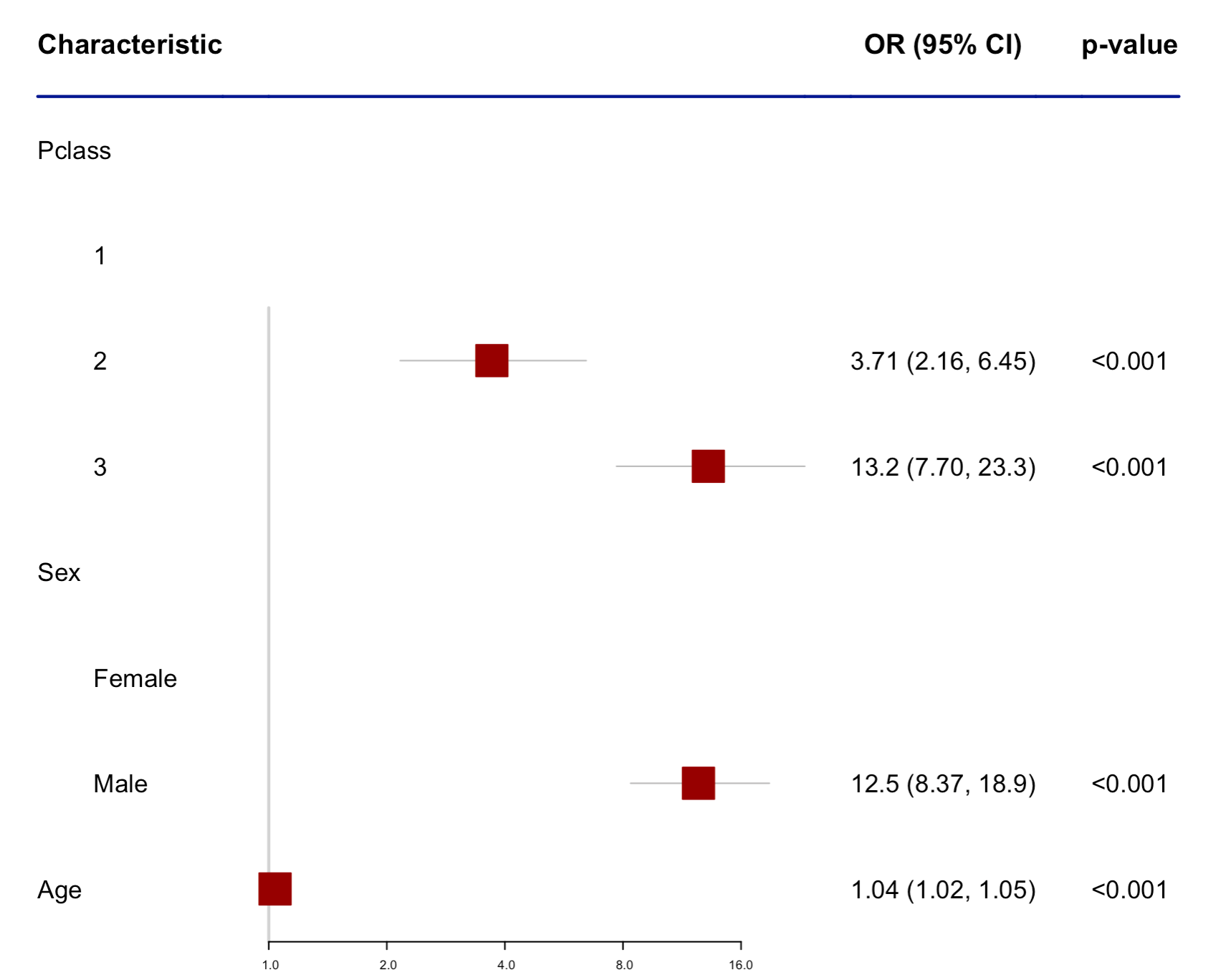
There are a lot of packages that can help create forest plots of model coefficients in R. It is a lot easier when you have created the model within R and then can directly go on to create the graph (compared to when you import the final coefficients and CIs from e.g., excel). Here we will go through some of the packages that can do this using the Titanic dataset from the Titanic package with survival as our outcome variable.
GGally
Code
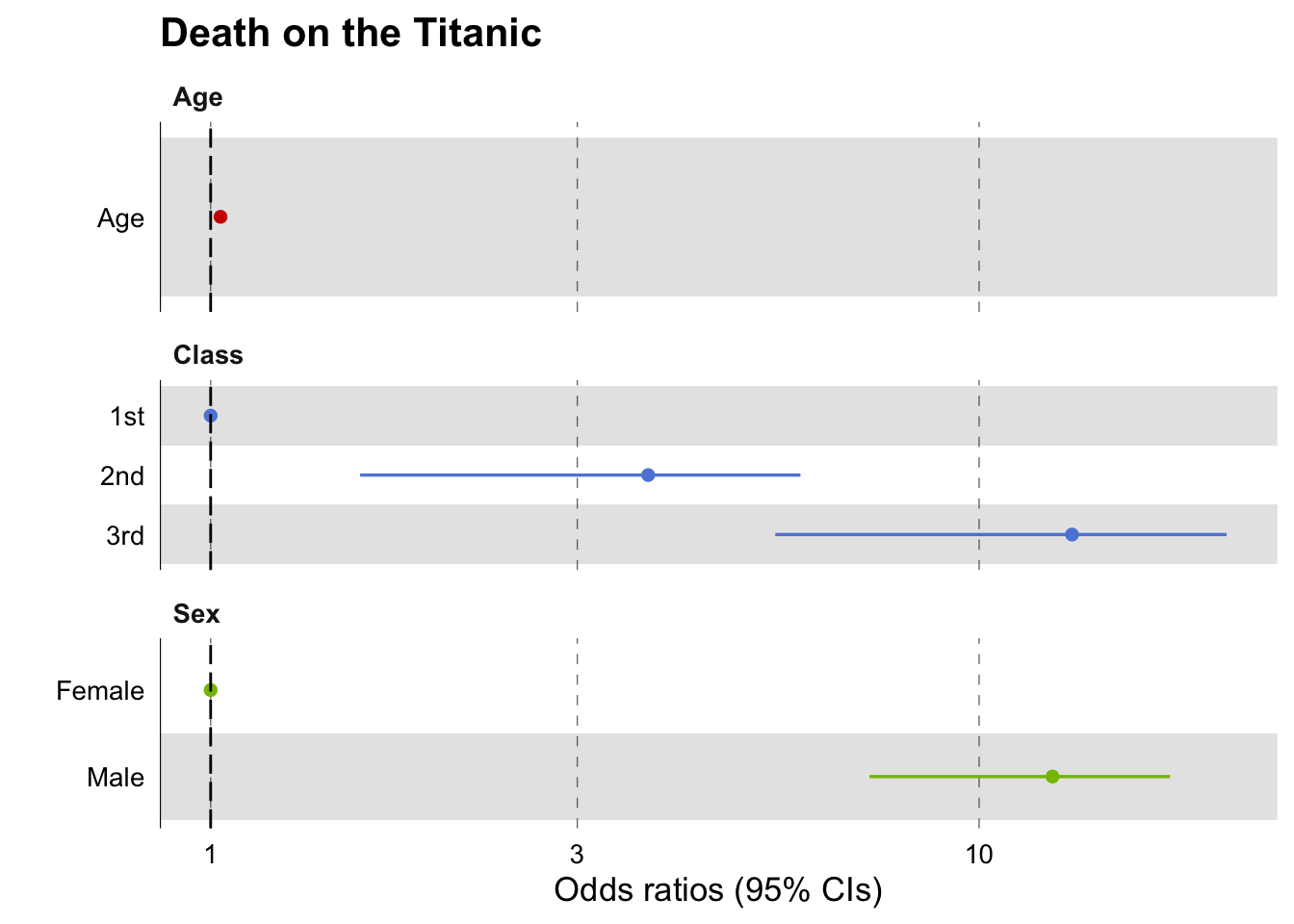
library(tidyverse)library(GGally)library(janitor)library(titanic)titanic_train %>%# Dataset usedselect(Pclass, Sex, Age, Survived) %>%# Keeping only the variables we wantmutate( # Making death 1 and survival 0, easier to interpret in graphSurvived =case_when( Survived ==1~0, Survived ==0~1 ),Pclass =factor(Pclass) # Class should be categorical ) %>%glm(Survived ~ ., data = ., family ="binomial") %>%# creating the modelggcoef_model( # Using the GGally functionexponentiate = T # exponentiating the results ) +labs(title ="Death on the Titanic", x ="Odds ratios (95% CI)") +# adding a title and a label for the X access ggsci::scale_color_nejm() +# Choosing a colour scheme, GGsci has many! theme(legend.position ="none", # Removing the legendtext=element_text(family="Times"), # specifiying Times New Roman Font for the whole plotplot.title =element_text(face="bold")) # Making title bold
GGally with labels
Here we are going to attach labels to each of the coefficients that will contain the odds ratio and the 95% CIs. This involves 4 steps:
1) Extract the actual coefficients and confidence intervals from the model object in a tidy dataset. We will use the package “broom.helpers” to do this.
2) Merge the odds ratio variable with the lower and upper confidence interval variables into a single variable. This makes it much easier to position the labels appropriately instead of trying to manage three individual labels. This can be done using either the “sprintf” function or the “unite” function which is what we will use here.
3) Create the forest plot (using GGally in this example)
4) Add the labels created in step 2 to the plot using geom_text_repel and position appropriately.
Code
library(tidyverse)library(GGally)library(janitor)library(broom.helpers)library(ggsci)library(ggrepel)# First create the model objectmodel_titanic <- titanic_train %>%# Dataset usedselect(Pclass, Sex, Age, Survived) %>%# Keeping only the variables we wantmutate( # Making death 1 and survival 0, easier to interpret in graphSurvived =case_when( Survived ==1~0, Survived ==0~1 ),Pclass =factor(Pclass) # Class should be categorical ) %>%glm(Survived ~ ., data = ., family ="binomial")# Getting estimates and CI's and merging into one columnestimates_cis <- model_titanic %>%tidy_and_attach(conf.int =TRUE, exponentiate = T) %>%# Estimates and CIs in tidy formattidy_add_reference_rows() %>%# Add a reference row for categorical variablestidy_add_estimate_to_reference_rows() %>%# Adding an estimate of "1" to reference rows for purpases of graph# tidy_add_term_labels() %>% tidy_remove_intercept() %>%# Model intercept won't be required for plotselect(variable, estimate, conf.low, conf.high, reference_row) %>%# Selecting only the variables we needadorn_rounding(digits =2) %>%# Rounding to 2 digits (applies to the whole dataframe)unite("CIs", # Name of new variable to be createdc(conf.low, conf.high), # Names of variables to be unitedsep =", ") %>%# The separator between the values of the two merged variablesunite("estimates", estimate:CIs, sep =" (") %>%mutate(estimates =paste0(estimates, ")"), # Adding a closed parenthesis to the new variablereference_row =replace_na(reference_row, FALSE), # Replacing any NAs in the "reference_row" category with FALSE, this happens in continuous variables e.g., Freqestimates =case_when( # Removing estimates from the reference rows reference_row =="FALSE"~ estimates )) model_titanic %>%ggcoef_model(exponentiate = T) +labs(title ="Risk factors for death", x ="Odds ratios (95% CI)") +scale_color_rickandmorty() +# Rick and Morty colour theme from GGscitheme(legend.position ="none",text=element_text(family="Times")) +geom_text_repel(aes(label = estimates_cis$estimates), # The labels we created earlierfamily ="serif", # The font we wish to usesize =3, # size of text of labelnudge_x =0.2, # nudge label left and rightnudge_y = .25, # nudge label up and downmin.segment.length =Inf, # removes lines that join labels to their pointxlim =c(-Inf, Inf), # Prevent labels being repelled by boundaries of graphylim =c(-Inf, Inf),color ="black")
FinalFit
FinalFit is slightly different in that you specifically create vectors of your outcome and explanatory variables and then feed the raw data to the function. Further manipulation of the graph is possible by using “plot_opts” and feeding GGplot functions.
Code
library(finalfit)library(tidyverse)library(janitor)library(ggsci)library(titanic)explanatory <-c("Pclass", "Sex", "Age")dependent <-"Survived"titanic_train %>%mutate( # Making death 1 and survival 0, easier to interpret in graphSurvived =case_when( Survived ==1~0, Survived ==0~1 ),Pclass =factor(Pclass) # Class should be categorical ) %>%or_plot( dependent, # Vector of dependent variables explanatory,# Vector of explanatory variablescolumn_space =c(-0.5, -0.25, 0.25), # Adjusting spacing of the textual columnstable_text_size =5, # Size of table texttitle_text_size =14, # Size of tabledependent_label ="Risk factors for death on the Titanic",suffix ="",plot_opts =list(xlab("OR (95% CI)")), # X labelbreaks =c(1, 5, 25) # X axis braks )
GTsummary
This uses GTsummary, the same package that creates beautiful tables of summary data and coefficients. This function is still in the experimental phase and is currently part of the bstfun package and not yet fully incorporated into GTsummary (hopefully happening soon).
Code
library(titanic)library(bstfun)library(gtsummary)library(tidyverse)titanic_train %>%# Dataset usedselect(Pclass, Sex, Age, Survived) %>%# Keeping only the variables we wantmutate( # Making death 1 and survival 0, easier to interpret in graphSurvived =case_when( Survived ==1~0, Survived ==0~1 ),Pclass =factor(Pclass) # Class should be categorical ) %>%mutate(Pclass =fct_recode(Pclass," 1"="1"," 2"="2"," 3"="3" ),Sex =fct_recode(Sex," Female"="female"," Male"="male" ) ) %>%glm(Survived ~ ., data = ., family ="binomial") %>%tbl_regression(exponentiate =TRUE) %>%modify_cols_merge(pattern ="{estimate} ({ci})",rows =!is.na(estimate)) %>%modify_header(estimate ="OR (95% CI)") %>%as_forest_plot(col_names =c("estimate", "p.value"),col = forestplot::fpColors(box ="darkred") )
Without R model object available
This page deals with the unenviable situation where you have raw data (estimates, CIs, standard errors) in tabular format without the actual R model object. Usually this arises as someone has made the ludicrous decision to do the original analysis in a program other than R. Not to worry, a few possibilities
We will first create some simulated data based on the Titanic dataset to experiment on. Running the first liens of code creates a dataframe called “df_forest_plot” which might be typical of what you might typically import from another program in before converting the data into a forest plot. It consists of
Variable names
Names of each level within categorical data
The number of observations within each level
Odds ratios
Upper and lower confidence intervals
A “reference” variable specifying whether or not this is the reference level in a categorical variable
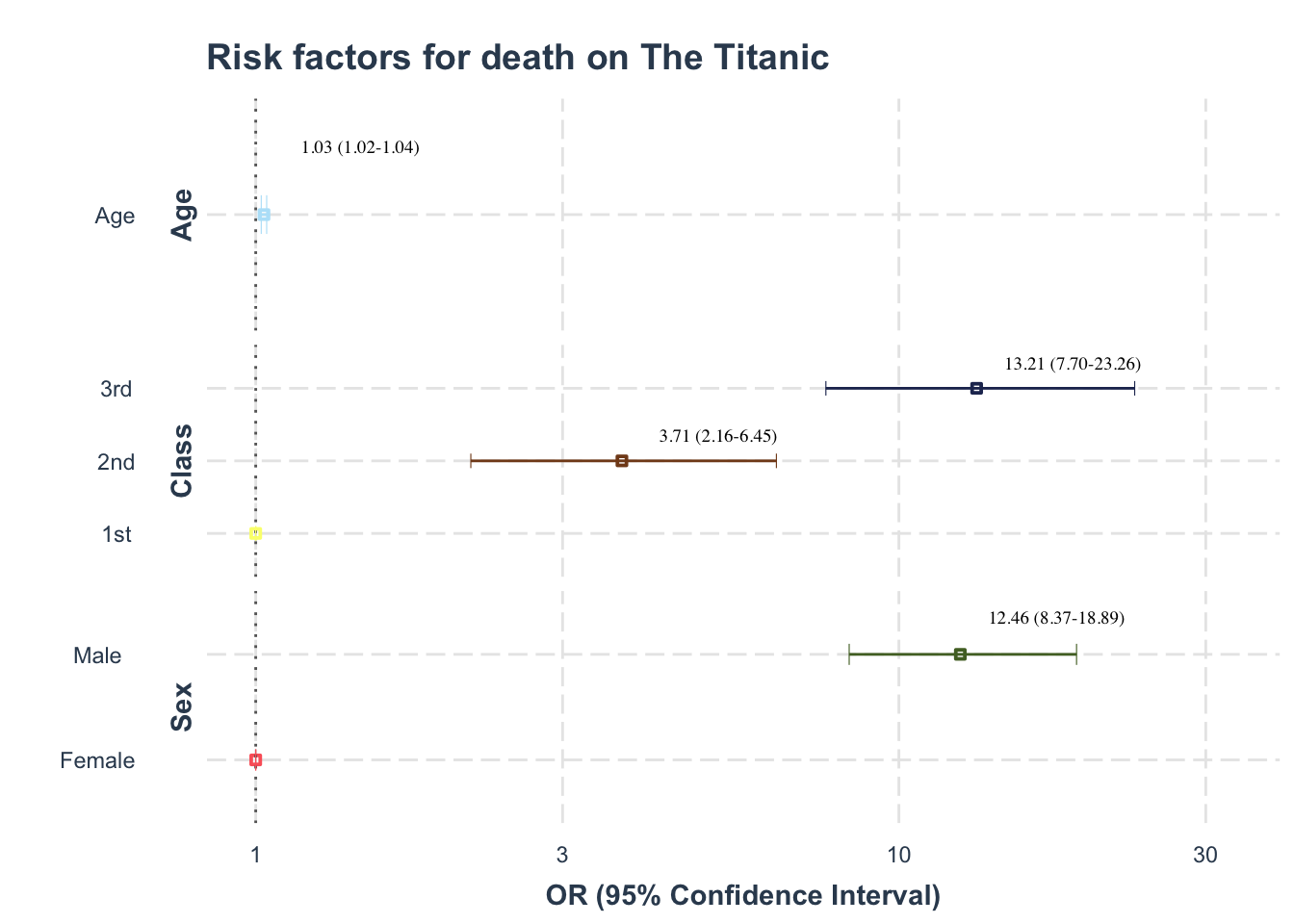
GGforestplot
For the GGforestplot package there are two manipulations we need to make to the data
1) Create standard errors and save them as a variable. This can be done with the “mutate” function and the formula
2) The reference rows have no odds ratio or standard errors so these will be removed from the graph. Often it is nice to have a dot on the Null line to indicate that this is the reference category. This can be done by replacing the NAs (AKA missing data) in the standard errors column with 0s and the NAs in the odds ratio column with 1s.
Code
library(tidyverse)library(ggforestplot)library(ggsci)# Creating simulated dataset df_forest_plot <- tibble::tribble(~variable, ~label, ~number, ~odds_ratio, ~lower_ci, ~upper_ci, ~reference, "Sex", "Female", 400, NA, NA, NA, TRUE,"Sex", "Male", 600, 12.46, 8.37, 18.89, FALSE,"Age", "Age", 1000, 1.03, 1.02, 1.04, NA,"Class", "1st", 200, NA, NA, NA, TRUE,"Class", "2nd", 200, 3.71, 2.16, 6.45, FALSE,"Class", "3rd", 600, 13.21, 7.7, 23.26, FALSE)df_forest_plot %>%mutate( # Creating standard error variable and replacing blanksstd_error = (upper_ci - lower_ci)/3.92,std_error =replace_na(std_error, 0),odds_ratio =replace_na(odds_ratio, 1) ) %>%ggforestplot::forestplot(estimate = odds_ratio, # Our odds ratiosname = label, # Variables to be includedlogodds = F,se = std_error, # Standard errorscolour = variable, # Grouping of colours according to variabletitle ="Death on the Titanic", # Titlexlab ="Odds ratios (95% CIs)"# X-axis label ) + ggforce::facet_col( # How the groupings are created, insert grouping variable below~ variable,scales ="free_y", ) +theme(legend.position ="none") +# Removing legendscale_x_continuous(trans='log10') +# Log scale X axisgeom_vline(xintercept =1, # Horiztonal line at 1 to indicate line of no effectlinetype ="longdash") +# Type of horizontal line, leave out completely for solid linescale_colour_startrek() # Star Trek colour scheme
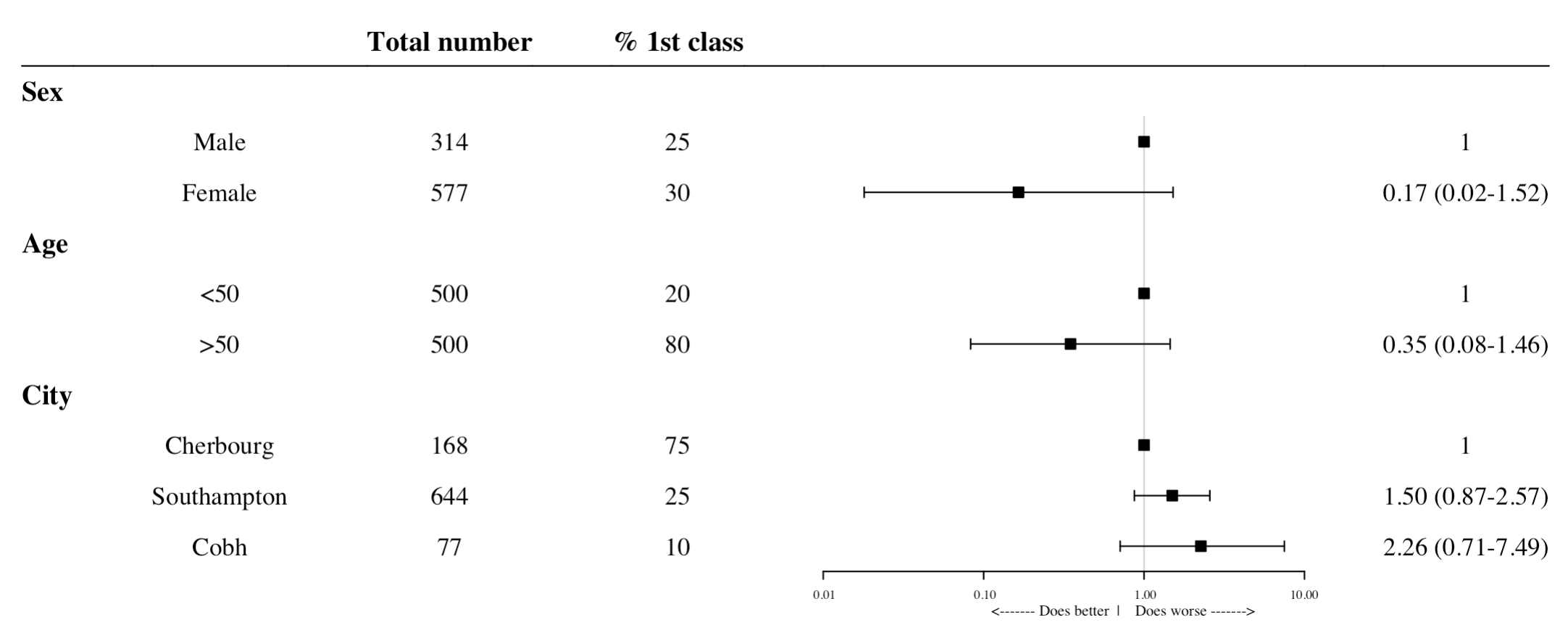
Forestplot
With this package the data should be laid out in the manner that you wish it to be printed in the plot. So each column in your data will be equivalent to a column in the plot with the same for rows. Missing data will result in gaps in the graph. It would probably be easier to manipulate the data to the desired format outside of R. A few points of note
The data must contain variables entitled “mean”, “lower” and “upper” which will be used to create the forestplot.
Using the reference row variable as a condition we will then set the values of the odds ratios and confidence intervals to 1 so as to include the reference rows in the graphs instead of excluding them completely if they had been left as missing data
To make the graph neater we will combine the odds ratios and confidence intervals into one variable named “labels” using the “sprintf” function.
Code
library(forestplot)library(tidyverse)# Simulated datadf_forestplot <- tibble::tribble(~variable, ~label, ~number, ~first_class, ~summary, ~mean, ~lower, ~upper, ~OR, ~reference,NA, NA, "Total number", "% 1st class", TRUE, NA, NA, NA, "OR", NA,"Sex", NA, NA, NA, TRUE, NA, NA, NA, NA, NA,NA, "Male", "314", "25", NA, NA, NA, NA, "-", TRUE, NA, "Female", "577", "30", NA, 0.165, 0.018, 1.517, "0.16", FALSE,"Age", NA, NA, NA, TRUE, NA, NA, NA, NA, NA,NA, "<50", "500", "20", NA, NA, NA, NA, "-", TRUE, NA, ">50", "500", "80", NA, 0.348, 0.083, 1.455, "0.35", FALSE, "City", NA, NA, NA, TRUE, NA, NA, NA, NA, NA,NA, "Cherbourg", "168", "75", NA, NA, NA, NA, "-", TRUE, NA, "Southampton", "644", "25", NA, 1.5, 0.87, 2.57, "1.5", FALSE, NA, "Cobh", "77", "10", NA, 2.26, 0.71, 7.49, "2.26", FALSE)# Mean, upper and lower must be named as suchdf_forestplot %>%mutate(labels =if_else(is.na(lower), "",sprintf("%.2f (%.2f-%.2f)",mean, lower, upper) ),labels =if_else( reference ==TRUE, "1", labels ),mean =if_else( reference ==TRUE, 1, mean ),lower =if_else( reference ==TRUE, 1, lower ),upper =if_else( reference ==TRUE, 1, upper ) ) %>% forestplot::forestplot(labeltext =c(variable, label, number, first_class, labels), # All the columns you wish to show in graphis.summary = summary, # The variables you want to boldgraph.pos =5, # Column number for forest plot positionboxsize =0.2, # Specifying size of boxes in plot, if left out boxes represent size of each group txt_gp =fpTxtGp(label =gpar(fontfamily ="Times")), # Fontxlog =TRUE, # Log scale on x axishrzl_lines =list("2"=gpar(lty =1)), # Where to place horizontal linescol =fpColors(line ="black"), # Colour of various elements in graphvertices =TRUE, # Whiskers for lines in plotxticks =c(.01, .1, 1, 10),xlab =" <------- Does better | Does worse ------->"# Crude method of inserting directional arrows, couldn't find better way )
GGplot with labels above each line
This guy only uses GGplot to create the graph, the advantage being flexibility. The labels have been created as above and then are “stuck” onto their corresponding values using “geom_text_repel”.
Code
library(tidyverse)library(jtools)library(ggsci)library(ggrepel)# Creating simulated dataset df_forest_plot <- tibble::tribble(~variable, ~label, ~number, ~odds_ratio, ~lower_ci, ~upper_ci, ~reference, "Sex", "Female", 400, NA, NA, NA, TRUE,"Sex", "Male", 600, 12.46, 8.37, 18.89, FALSE,"Age", "Age", 1000, 1.03, 1.02, 1.04, FALSE,"Class", "1st", 200, NA, NA, NA, TRUE,"Class", "2nd", 200, 3.71, 2.16, 6.45, FALSE,"Class", "3rd", 600, 13.21, 7.7, 23.26, FALSE)df_forest_plot %>%mutate(combined =ifelse(is.na(lower_ci), "",sprintf("%.2f (%.2f-%.2f)", odds_ratio, lower_ci, upper_ci ) ),odds_ratio =if_else( reference ==TRUE, 1, odds_ratio ),lower_ci =if_else( reference ==TRUE, 1, lower_ci ),upper_ci =if_else( reference ==TRUE, 1, upper_ci )) %>%ggplot(aes(x = label, y = odds_ratio, ymin = lower_ci, ymax = upper_ci)) +geom_pointrange(aes(col = label), shape =22, size = .3) +geom_hline(yintercept =1, linetype ="dotted", color ="grey40") +xlab("") +ylab("OR (95% Confidence Interval)") +geom_errorbar(aes(ymin = lower_ci, ymax = upper_ci, col = label), width =0.2, cex =0.2) +facet_wrap(variable ~ ., strip.position ="left", nrow =10, scales ="free_y") +scale_y_continuous(trans ="log10") +theme_nice() +theme(legend.position ="none" ) +coord_flip() +labs(title ="Risk factors for death on The Titanic") +scale_color_rickandmorty() +geom_text_repel(aes(label = combined),family ="serif", # fontsize =2.5, # size of text of labelnudge_x =0.35, # nudge label up and downnudge_y = .15, # nudge label left and rightmin.segment.length =Inf, # removes lines that join labels to their pointxlim =c(-Inf, Inf), # Prevent labels being repelled by boundaries of graphylim =c(-Inf, Inf))